Monolith Modernisation, Part 2: Migration Strategies
In this article, I dive deeper into the high-level strategies that can get you out of the pain of a dysfunctional monolith!

In the previous post, I explored how a dysfunctional monolith comes into being, covered some organizational aspects of the change track, and listed three strategies to come to a more modular architecture that can deliver more business value faster.
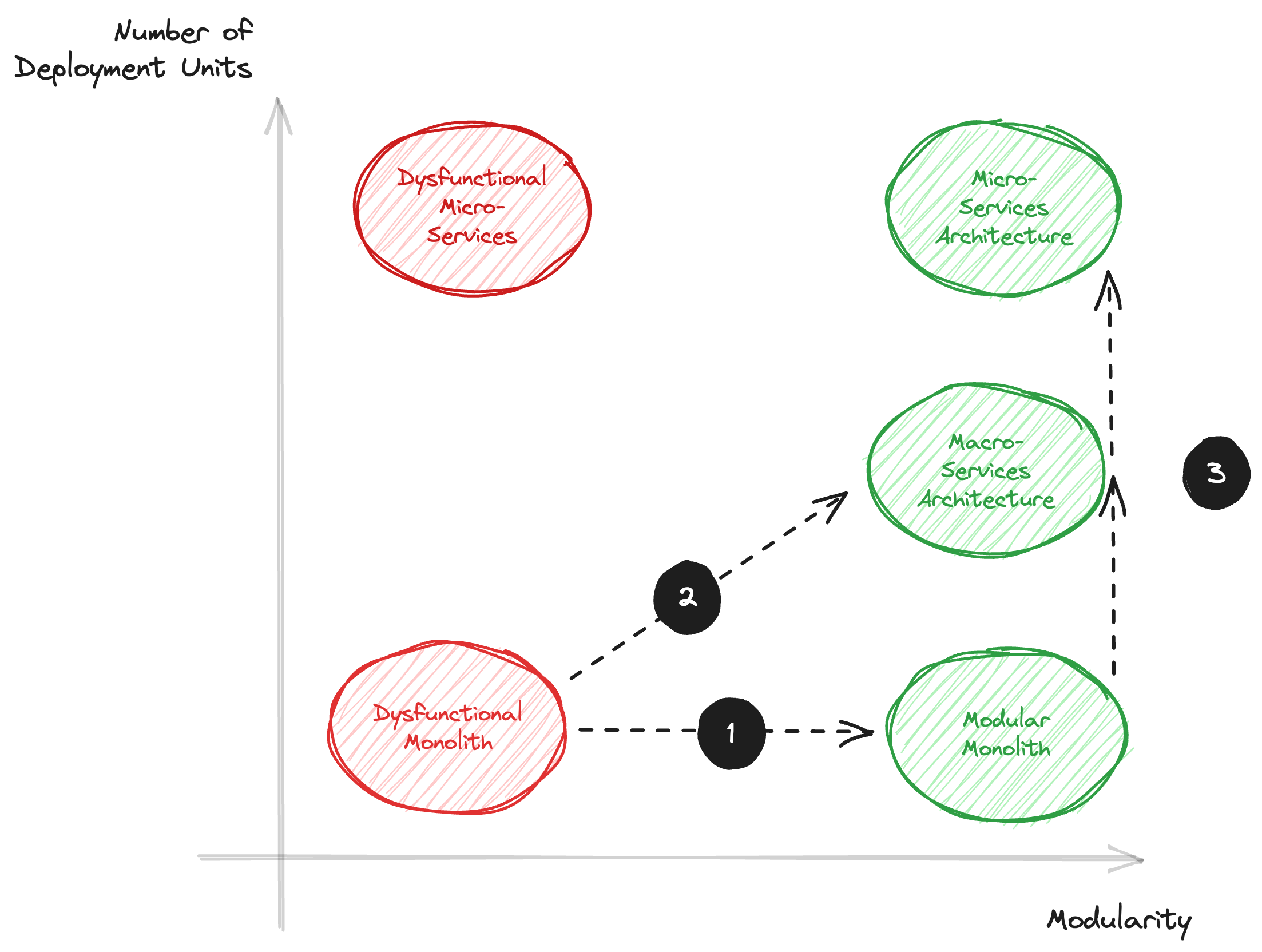
In this 2nd part of the series about monolith migration, I dive into more detail about each of these strategies, highlighting the benefits and limitations. I also indicate when each strategy makes sense. Finally, I provide some high-level diagrams to make it all more tangible.
In the 3rd part of this series, I will explore the technical patterns and tactics that will help you in the journey. Finally, part 4 will cover a day in the life of a team working on such a migration.
But let's first start with the high-level strategies!
Splitting up the Monolith into Modules
The 1st strategy is to leave the number of deployment units as is and gradually make the code base more modular.
These changes will happen within the same deployment unit. As a consequence (and limitation), this will happen in the current technology (e.g. PHP remains PHP) and possibly version (eg. Spring Boot versions cannot be mixed). Also, the build & deployment pipelines will remain shared among the legacy code and the new code.
Despite these limitations, this low-risk option remains in many cases the best 1st step and has the big advantages that (i) the data remains immediately consistent and (ii) there is no network latency or network hick-up to be dealt with. It also allows teams to build knowledge, improve engineering practices, and become more proficient in thinking in smaller modules, before tackling the additional challenges of distributed architectures.
Let’s make this a bit more concrete by applying the migration steps to the sample architecture:
- We have an in-house developed front (a single-page application - SPA) that uses a REST/HTTP internal API to talk to the back end. (if the application does server-side rendering of HTML, the changes will be easier as no backward compatibility or synchronization among different components is needed)
- API consumers are 3rd party systems that connect to our exposed API.
- The back end is a single deployment unit with tightly coupled and intertwined code that shares a single data set with a common data model.
- The blue parts of the diagram are the changes compared to the starting situation.
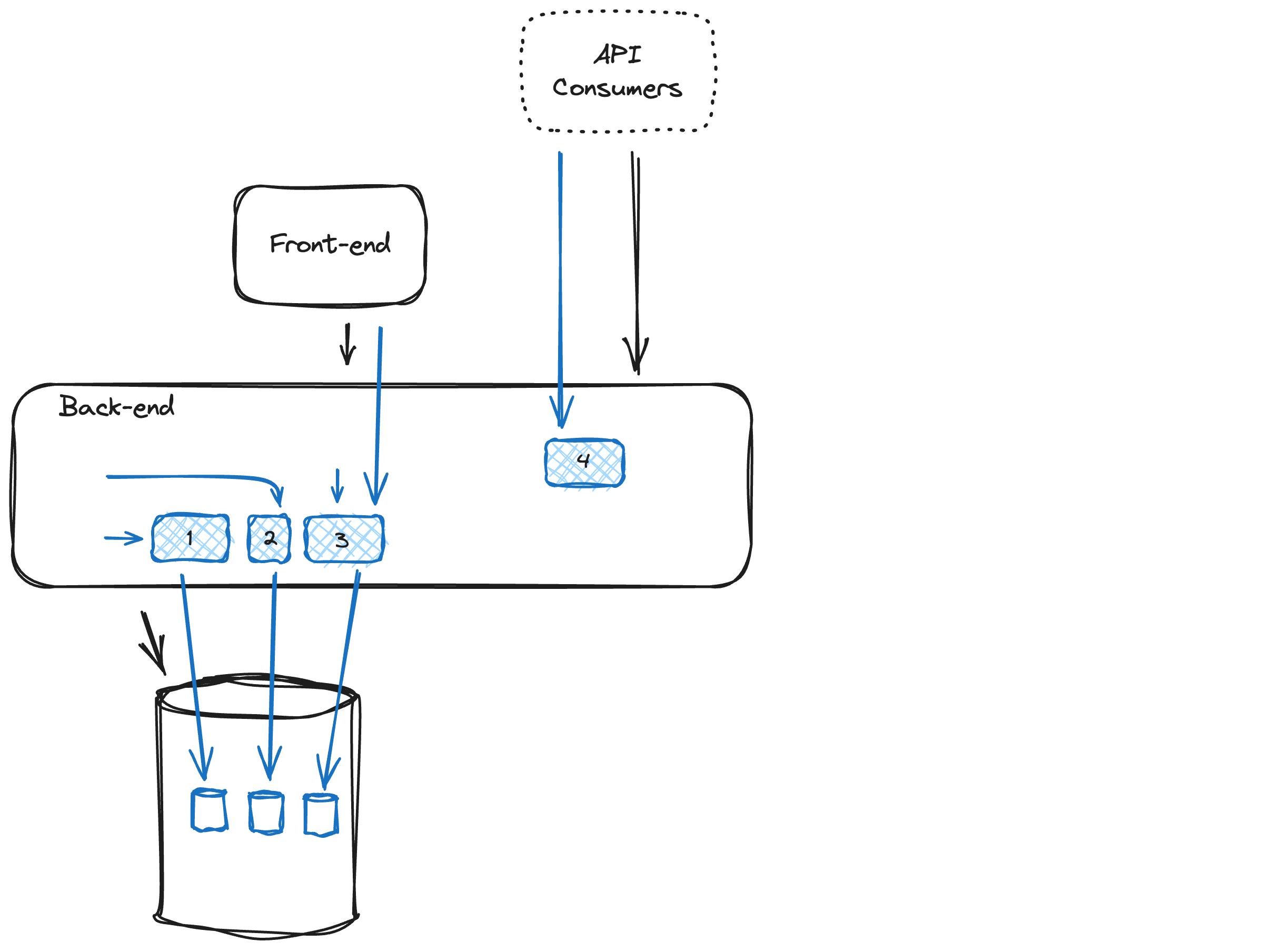
As a first step, we introduce a module that exposes its functionality via a clear (and preferably explicit) interface and operates on a delineated dataset. Important to note here is that splitting of the module should be done on a functional boundary, not a technical one. It is also important to strike the right balance: creating small modules that become very chatty, causes strong interdependencies while leaving modules too large will make it hard to extract them promptly from the monolith.
Common examples of modules that do not have (internally or externally) exposed interfaces are "payment processing", "printing", etc ... Each of the new modules should have proper automated tests, a strong description of the domain, and proper isolation of the incoming and outgoing integrations to facilitate easy and reliable evolutions (hexagonal architectures work great for this).
Once available, the monolith will start calling this functionality instead of the legacy implementation. Please note that the module itself will NOT use the monolith's code or functionality. This ensures that the module remains independent from the evolutions of the monolith.
It is always safe to validate the (positive) outcomes of your first experiment and confirm the learnings, so try to find a 2nd implementation before tackling a new problem. Introducing module 2 does exactly that.
Neither step 1 nor step 2 should have an impact on the users of the app. Even though the implementation may (drastically) change, the existing interfaces to the front-end or API consumers remain untouched.
This is something we will not keep as a constraint when tackling the 3rd module in our fictional scenario: let’s say a JSON over HTTP interface is replaced by a new version. As the front-end is also in-house developed, changing the front-end to align with the new synchronized can be synchronized across developers or teams. There is no need for a long-lived multi-versioned transition period.
This simplifying factor is in turn no longer withheld when we create module 4. Indeed, external API consumers will need to start consuming the new interface and hence adapt their implementation. This will take time (months at best) and does not allow for a quick switch. Both versions of the interface will need to co-exist.
During the steps described above, several learnings will take place:
- How to define modules with coherent functional scope and clear interfaces?
- How to split parts of the shared dataset and only make it accessible to a specific module without transactions across modules. If we do not take this step, we still have tightly coupled modules and we are simply building a different monolith with painful disfunctions.
- How to ensure no regressions take place when a new module is put into use?
- How to troubleshoot and debug functionality that spans multiple modules and parts of the legacy monolith code?
- How to manage multiple versions of the exposed API?
- …
The ultimate goal of breaking the monolith into functional components like this is to allow functional evolutions that change only one or very few components at a time. If done right, this will drastically reduce the cognitive load when working on such a change. Which in turn will make it much easier to deliver functionality faster.
In the next part of the series, technical patterns and tactics will be discussed in more detail.
Splitting Off Modules to a Limited Number of (Macro-)Services
A 2nd strategy is to make minimal changes to the current deployment unit and put a new deployment unit next to it.
In the context of this article, a deployment unit can be different things: it can be a jar that is running on a physical server, it can be a container on a public cloud or even a serverless function. Key properties of deployment units are (i) that one has no direct technical dependency on another and (ii) that each deployment unit has a separate deployment lifecycle in a technical sense of the word. Functional dependencies may be still in place which leads to interdependencies and synchronized deployments. this is an indicator that the module boundaries are not yet optimal!
Introducing a separate deployment unit is needed for technical reasons if one of the goals of the modernization is to change the programming language (e.g. PHP to Go, Node.js to Rust). It is also useful if the ultimate goal is to evolve toward smaller deployment units (see strategy 3 below).
Let’s make this visual on the sample architecture diagram (blue indicates changes).
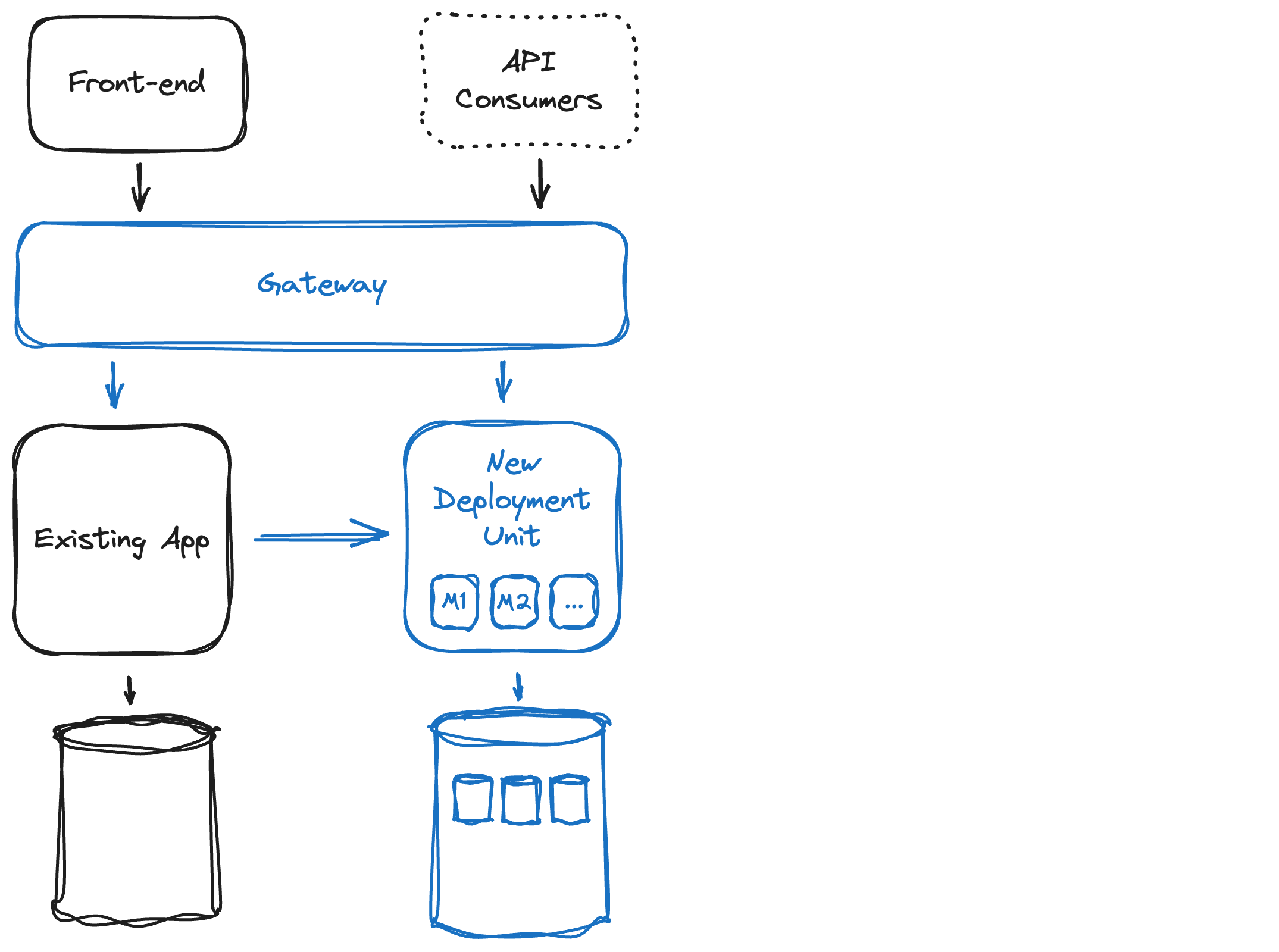
A gateway can help to direct the traffic from the front-end and API consumers to the right place: towards the existing app if the function is still there, and towards the new deployment unit if the function has been moved over. In more advanced migration scenarios, one could even think about moving users in batches to make sure there is no fundamental regression.
The new deployment unit will contain the new modules. The legacy code can call new functionality through interfaces exposed by the new modules. Note that the arrow from the existing app to the new code is one way: the new modules should not depend on the monolith. Whether the calls to the new deployment unit pass over the gateway or not is a tactical choice that depends on the specifics of the gateway.
During these steps, learnings of strategy 1 need to be extended with additional aspects:
- Network communication: the deployment units will typically communicate through network-based protocols (HTTP, gRPC, Messaging, …). This comes with several challenges: additional code & libraries to use, additional latency, and network failures, …
- Security: If you are dealing with highly sensitive data, security is a critical element. It is important to ensure that the user's information propagates reliably and safely across the entire app, also during the migration phase. Similarly, the (audig) logging needs to be kept reliable during the entire migration phase
A new (modular) application can be achieved via a big-bang rewrite or a gradual migration. I am strongly biased towards a gradual migration, for several reasons: (i) rewriting an entire application at once will not create the feedback cycle that is the basis for learning (ii) a big bang data migration is a big risk and is a huge endeavor in terms of pre-release validation and (iii) if you run out of budget before having finished the entire rewrite, you end up with no benefit at all…
Gradually Making the modules more independent & smaller (in terms of functional scope)
This brings us to the third step in the migration strategy, which consists of making the deployment units smaller and smaller, evolving to the true micro-services architecture. As you may remember from the diagram at the top of the article, this is an "advanced" migration strategy and needs careful consideration.
At a high level, there are 2 main drivers for splitting up into different deployment units: (i) improved team organization and (ii) specific - typically non-functional requirements - for part of the application.
The first reason applies when the functional area of a deployment unit is becoming larger than what a team of 4-8 people can manage. The split will create smaller units in terms of functional scope that can evolve (and be deployed) independently, allowing 2 or more teams to work truly autonomously one from the other. Indeed: the lifecycle of modules must be independent for the teams to be autonomous and this can only happen with different deployment units.
A second reason for creating separate deployment units is to adapt to specific non-functional requirements:
- Working with multiple deployment units will make it possible to deploy one part of the application without causing downtime for another part of the application, especially if the communication among the modules is asynchronous.
- If one component needs to scale based on the time of the day (eg. overnight batch reporting), while others need to scale based on the number of users (e.g. peaking during summer), having different deployment units with different underlying hardware resources will prove very useful.
- Another example is security: certain functionality of an application may be subject to location constraints (e.g. running in the country of residence of the citizens), while other parts of the application can run anywhere in the world.
But these benefits come at a price: besides the "simple" mechanics of releasing and deploying a lot of modules, it also means a lot of knowledge must be built up around distributed applications. Think of remote interfaces, contract testing, multiple versions, the effects of networking communication, and maybe the most difficult one: eventual consistency of data.
The following diagram shows a possible evolution of the setup from the 2nd strategy.
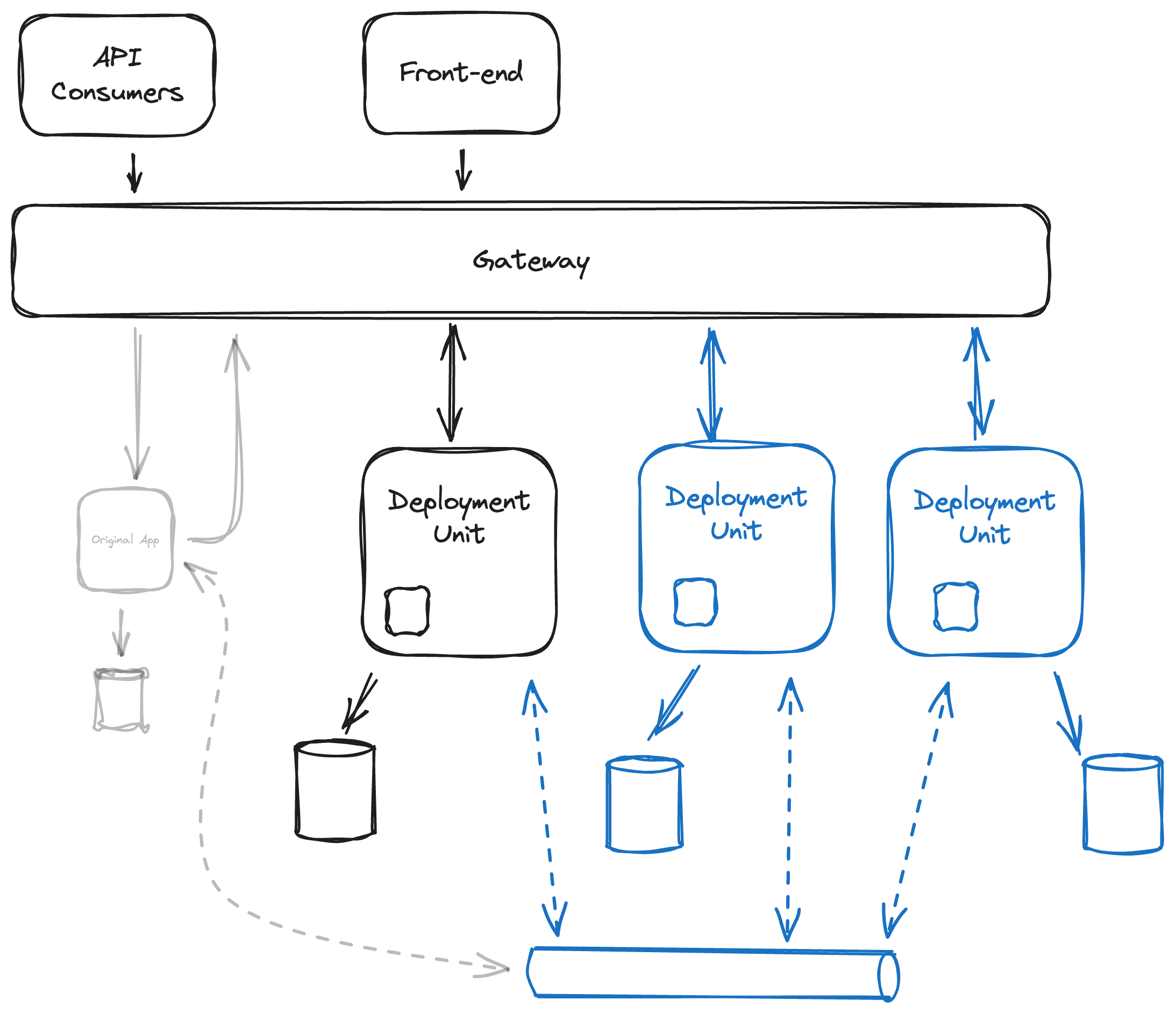
The gateway will connect to multiple deployment units and deployment units. The deployment units can also communicate in real-time with each other through the gateway. Each deployment unit has its own storage, one independent from the other. As there are more deployment units and modules, it will become more & more beneficial to use asynchronous communication, facilitated through some messaging infrastructure.
One thing to keep in mind and (re-)consider from time to time: if parts of the dysfunctional application are not part of your core, replacing them with a 3rd party application or services you procure is a viable option as well! This may free up the time & budget of the team to focus on (and differentiate with) a better core. As you can imagine here as well: the modularity of your code will help you to choose the optimal implementation approach!
Conclusions and Next Steps
The challenges of a migration project away from a dysfunctional monolith, in either strategy, are not to be taken lightly! The time & budget to significantly improve what grew over the years will be significant. The team (and the business) will need to learn a lot and the behavior of new technologies will often raise eyebrows… Nevertheless, evolving to a more modular architecture is a prerequisite for the new wave of success and must be taken when the time is there!
In the following parts of this series, I will dive deeper into the technological aspects that help in the realization of each of these strategies (part 3) and the day-to-day challenges you may encounter during a migration track (part 4).
References
 ddd-crew
ddd-crew